七、图
# 六、图
# 图的基本概念
# 图的定义
图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合。
# 图的相关术语
# 无向边
若顶点vi到vj之间没有方向,则称这条边为无向边,有无序偶对(vi,vj)来表示。
# 无向图
如果图中任意两个顶点之间的边都是无向边,则称该图为无向图
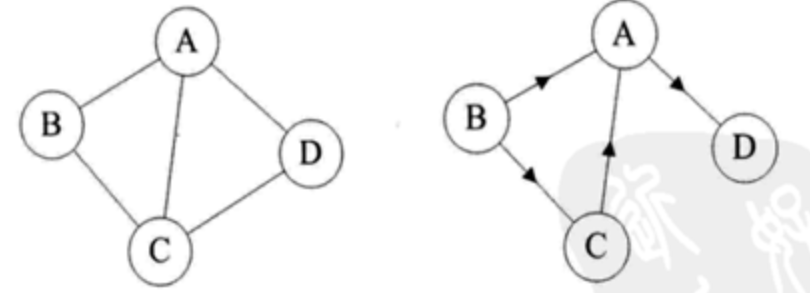
# 有向边
若从顶点vi到vj的边有方向为有向边,也称为弧,用 有序偶< vi, vj> 来表示,vi称为弧尾,vj称为弧头。
# 有向图
如果图中任意两个顶点之间的边都是有向边,则称该图为有向图。
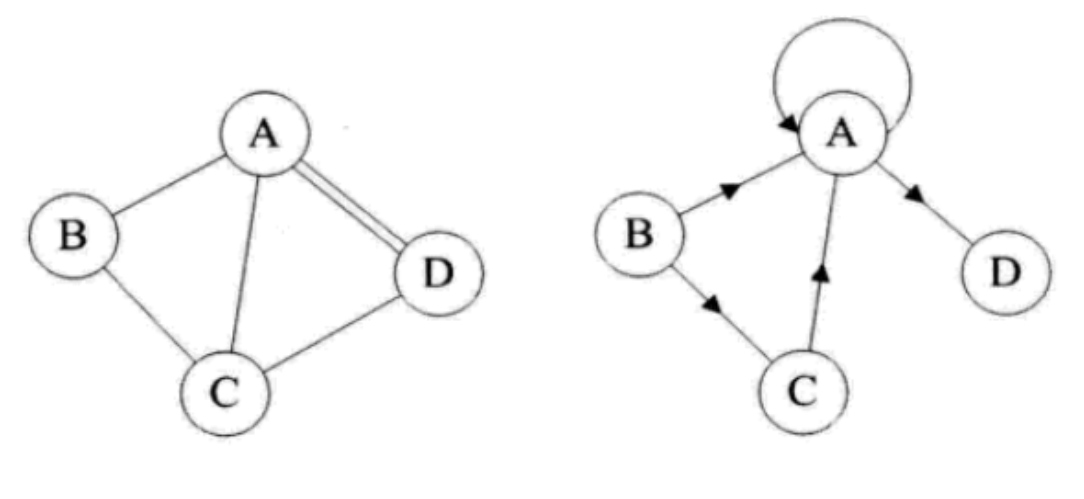
# 简单图
在图中,如果不存在顶点到其自身的边,且同一条边不重复出现,则称这样的图为简单图。
# 无向完全图
在无向图,如果任意两个顶点之间都有存在边,则称该图为无向完全图。
# 有向完全图
在有向图中,如果任意两个顶点之间都存在互为相反的弧,则称该图为有向完全图
有很少的边或弧的图称为稀疏图,反之称为稠密图 权:有些图的边或者弧具有与他相关的数字,这个相关的数称为权
# 网
这种边带权值的图叫网
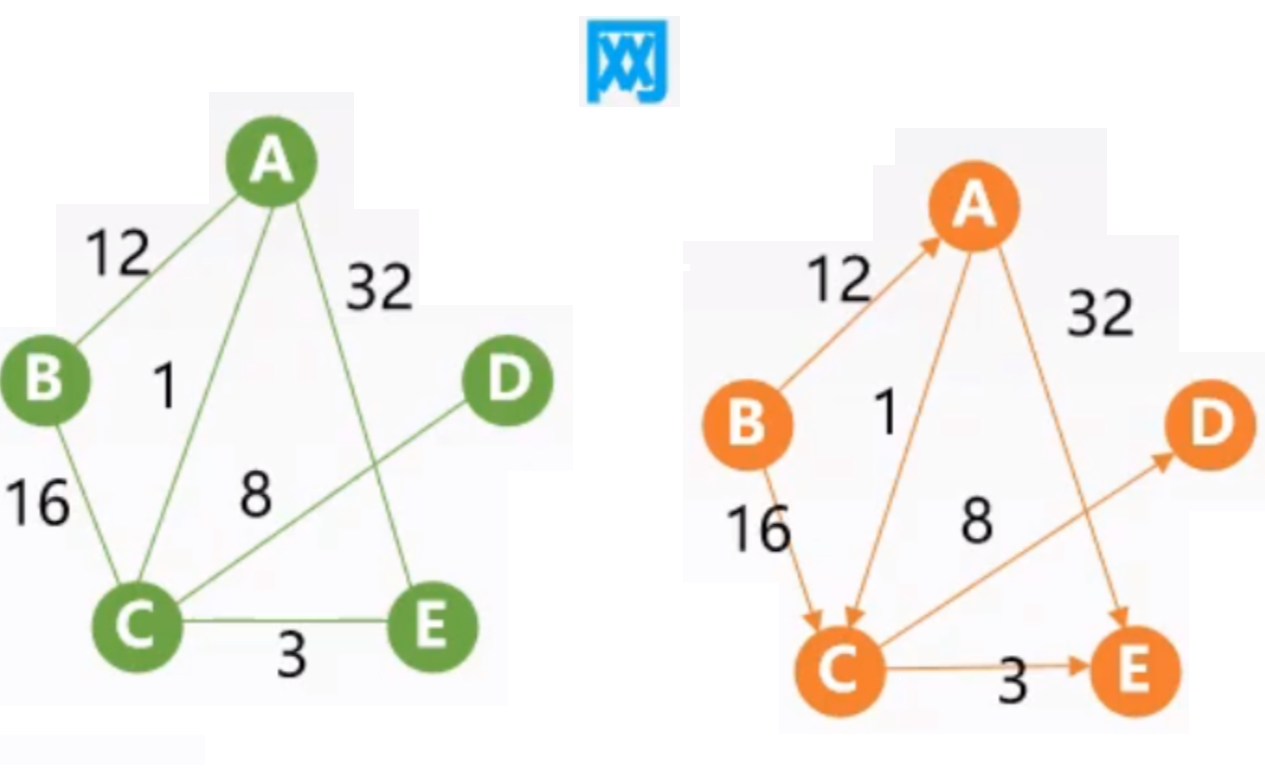
# 图的存储结构和基本运算算法
# 图的存储结构
邻接矩阵
邻接矩阵用两个数组保存数据。一个一维数组存储图中顶点信息,一个二维数组存储图中边或弧的信息。
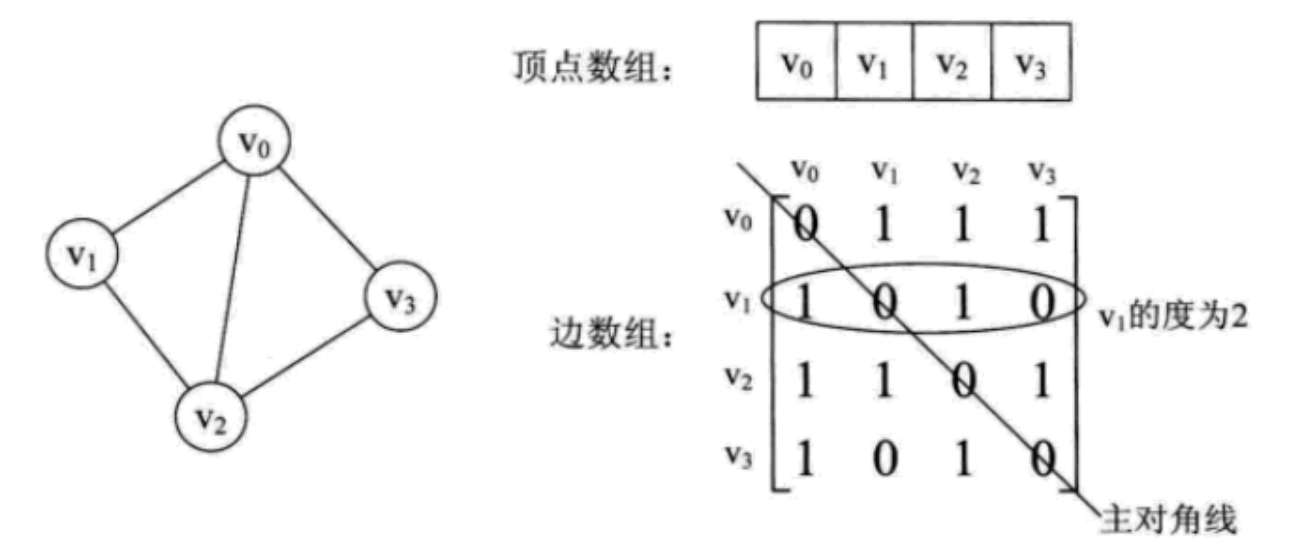
邻接矩阵的表示
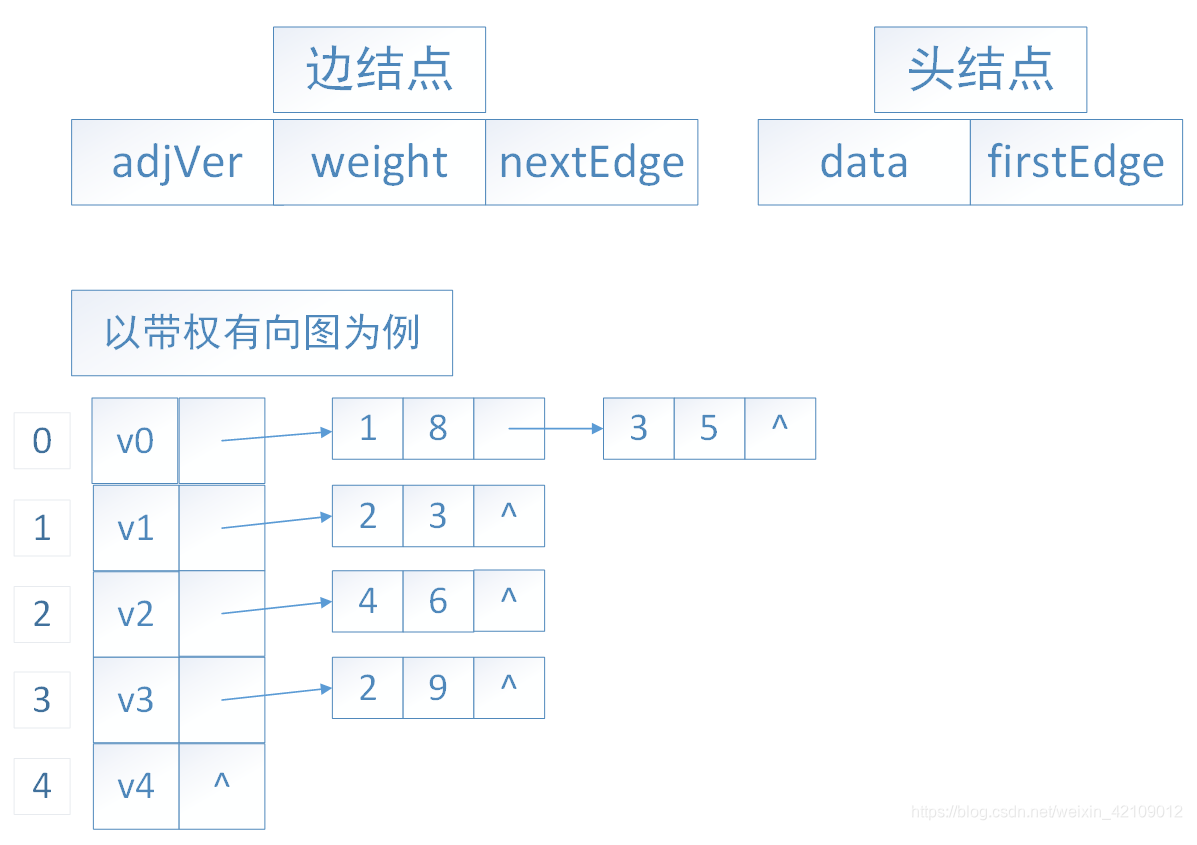
其他存储结构
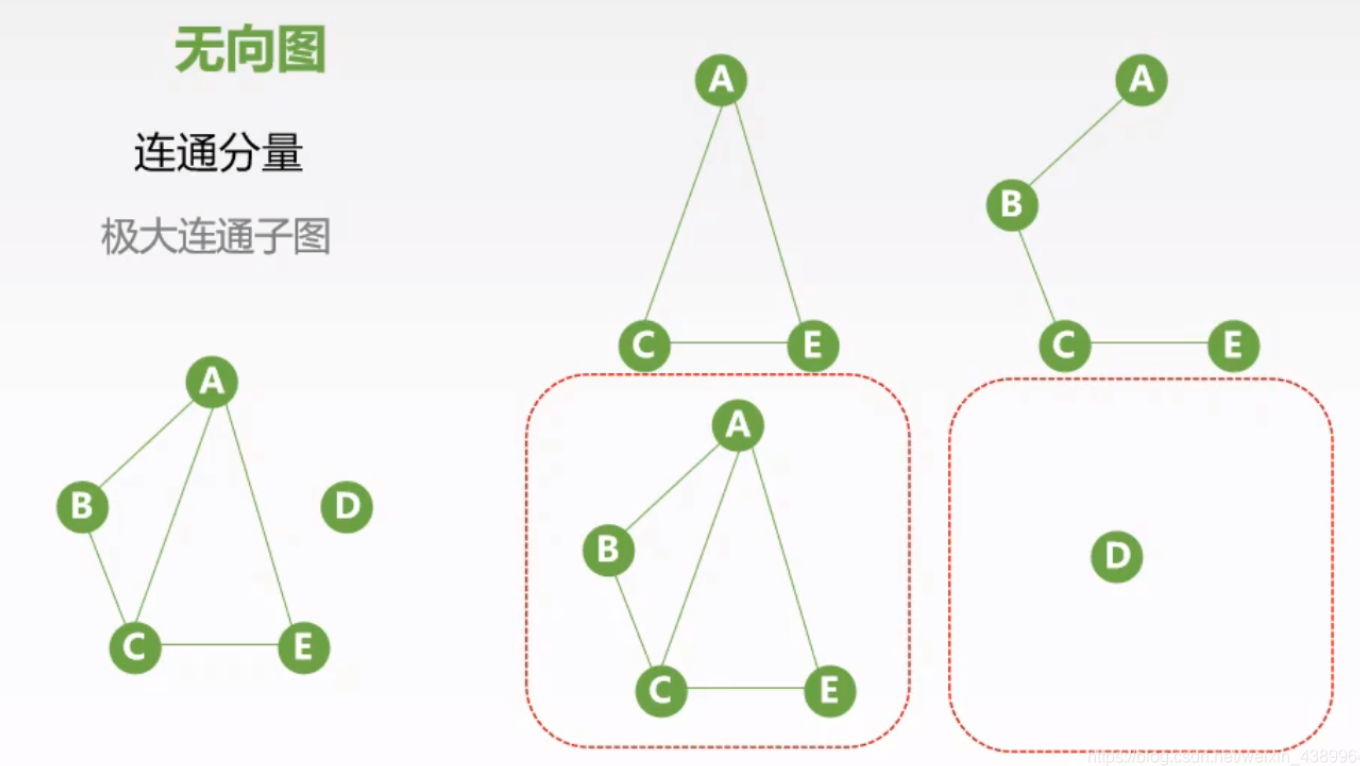
邻接表:是由每个顶点以及它的相邻顶点组成的
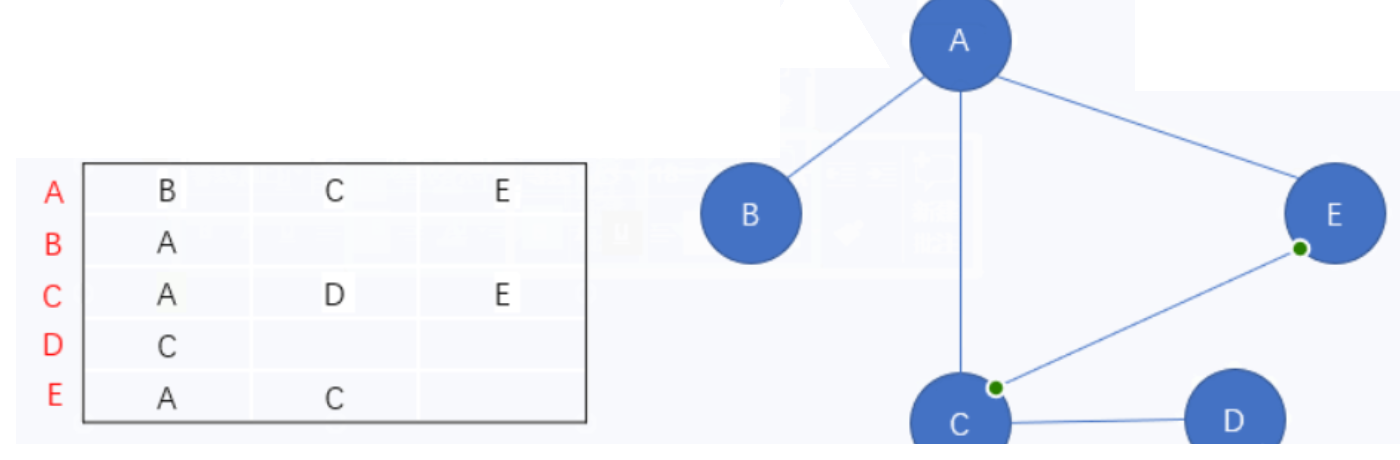
如上图:图中最左侧红色的表示各个顶点,它们对应的那一行存储着与它相关联的顶点
顶点A与 顶点B 、顶点C 、顶点E 相关联顶点B与 顶点A 相关联顶点C与 顶点A 、顶点D 、顶点E 相关联顶点D与 顶点C 相关联顶点E与 顶点A 、顶点C 相关联
十字链表:用于存储有向图;
邻接多重表:用于存储无向图
# 图的算法实现
图的结构体创建
typedef struct {
VexType vexs[MAXVEXNUM];//点的集合
ArcCell arcs[MAXVEXNUM][MAXVEXNUM];//边的集合
int vexNum, arcNum;
}MyGraph;
2
3
4
5
图的创建
void CreateDGraphFromConsole(MyGraph &G, int vexNum, int arcNum){
G.vexNum=vexNum;
G.arcNum=arcNum;
for(int i=0;i<G.vexNum;i++){
cin>>G.vexs[i];
}
for(int i=0;i<G.vexNum;i++){
for(int j=0;j<G.vexNum;j++){
G.arcs[i][j]=0;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
图的删除
void DispGraph(MyGraph& G){
for(int i=0;i<G.vexNum;i++){
cout<<G.vexs[i];
for(int j=0;j<G.vexNum;j++){
cout<<" "<<G.arcs[i][j];
}
cout<<endl;
}
}
2
3
4
5
6
7
8
9
# 图的遍历
BFS算法
BFS,即图的广度优先搜索遍历,它类似于图的层次遍历,它的基本思想是:首先访问起始顶点v,然后选取v的所有邻接点进行访问,再依次对v的邻接点相邻接的所有点进行访问,以此类推,直到所有顶点都被访问过为止。
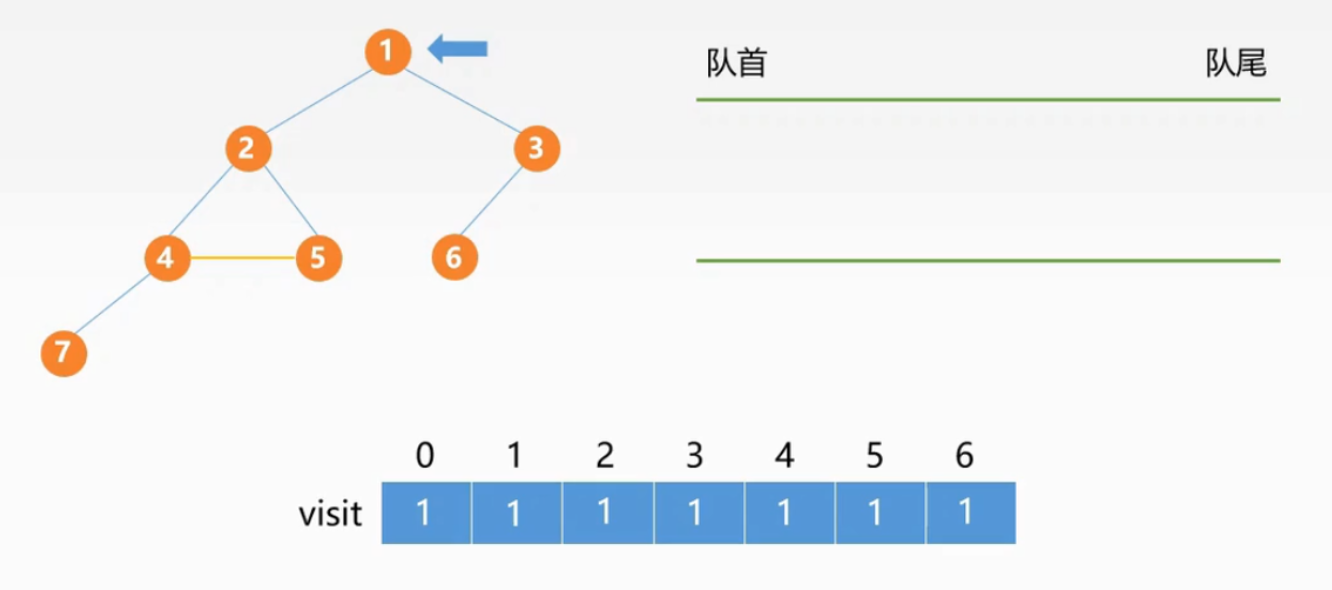
BFS广度优先遍历代码:
bool visited[MAX_VERTEX_NUM]; //访问标记数组 访问置为true
void BFSTraverse(Graph G){
for(int i = 0; i<G.vexnum; i++)
visited[i] = false; //初始化标记数组
InitQueue Q;
for(i = 0; i<G.vexnum; ++i) //从头开始遍历
if(!visited[i]) //保证每一个结点都进行BFS
BFS(G,i);
}
void BFS(Graph G, int V){
visit(v); //访问初始的顶点
visited[v] = true; //标记上面防止二次访问
EnQueue(Q, v); //BFS需要利用队列,类似于二叉树的层次遍历
while(!IsEmpty(Q)){
DeQueue(Q, v); //出队后下一步就是寻找v所有的连接结点
for(int w = FirstNeighbor(G, v) ; w >= 0; w = NextNeighbor(G, v))
if(!visit[w]){ //如果结点未被访问过
visit(w);
visited[w] = true; //标记
EnQueue(Q, w); //进队
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
BFS求解单源最短路径问题------------非带权图
void BFS_MIN_Distance(Graph G, int u){
//d[i]表示从u到i结点的最短路径
for(int i = 0; i < G.vexnum; ++i)
d[i] = 0xffffffff; //最大值
visited[u] = true; d[u] = 0;
EnQueue(Q, u);
while(!IsEmpty(Q)){
DeQueue(Q, u); //出队后下一步就是寻找v所有的连接结点
for(int w = FirstNeighbor(G, u) ; w >= 0; w = NextNeighbor(G, u))
if(!visit[w]){ //如果结点未被访问过
visited[w] = true; //标记
d[w] = d[u] + 1; //路径长度加一
EnQueue(Q, w); //进队
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
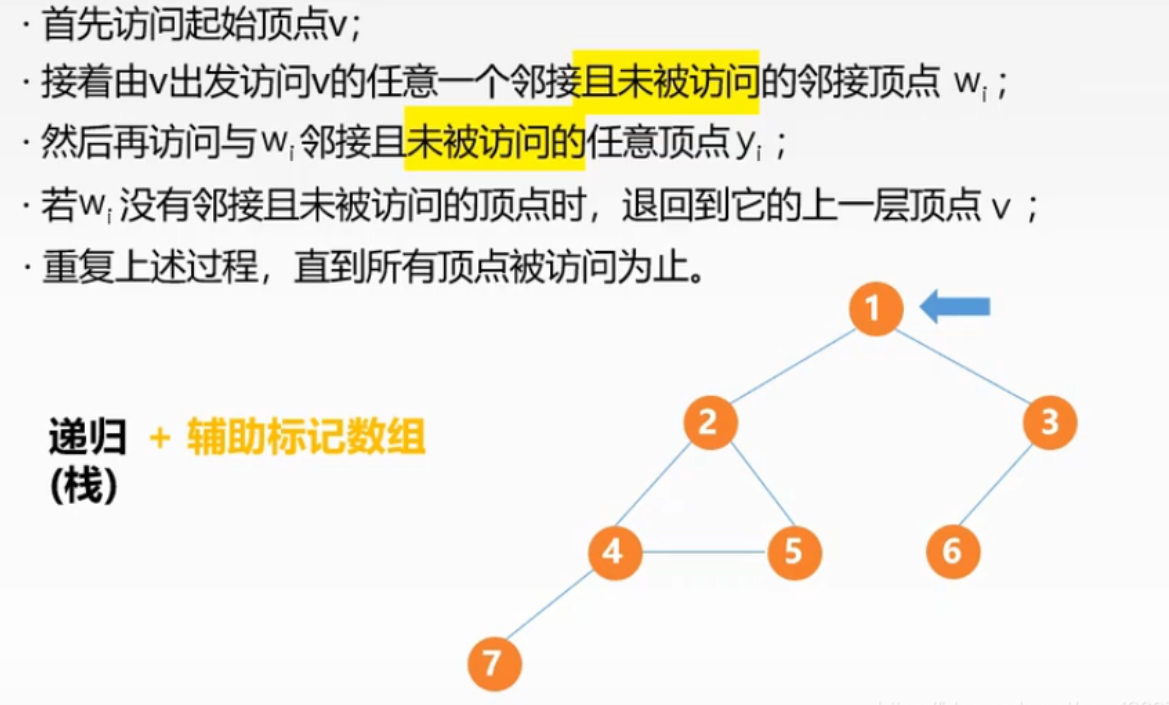
深度优先遍历 类似于树的先序遍历。
基本思想:先访问初始顶点v,然后从v出发访问与v紧接且未被访问的任意顶点w1然后无限套娃访问w1的紧接为被访问的顶点,当不能在往下继续访问时,依次退回最近被访问的顶点,若这个顶点还有未被访问的顶点,则从该顶点重蹈覆辙 性能分析: 空间复杂度:O(V) 因为递归算法需要用到一个递归工作栈 时间复杂度:邻接矩阵:O(v*v) 邻接表:O(V + E)
bool visited[MAX_VERTEX_NUM]; //访问标记数组 访问置为true
void DFSTraverse(Graph G){
for(int i = 0; i<G.vexnum; i++)
visited[i] = false; //初始化标记数组
for(i = 0; i<G.vexnum; ++i) //从头开始遍历
if(!visited[i]) //保证每一个结点都进行DFS
DFS(G,i);
}
void DFS(Graph G, int v){
visit(v);
visit[v] = true;
for(int w = FirstNeighbor(G,v); w >= 0; w = NextNeighbor(G,v,w)){
if(!visited(w)){
DFS(G, w); //递归每次遍历结点的第一个
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
DFS算法
深度优先搜索(Depth First Search)一种用于遍历或搜索树或图的算法。 沿着树的深度遍历树的节点,尽可能深的搜索树的分支。当节点v的所在边都己被探寻过或者在搜寻时结点不满足条件,搜索将回溯到发现节点v的那条边的起始节点。整个进程反复进行直到所有节点都被访问为止。属于盲目搜索,最糟糕的情况算法时间复杂度为O(!n)。
DFS采用非递归遍历 ------图采用邻接表形式
//用栈来模拟了一个递归工作栈
void DFS_Non_RC(Graph G, int v){
int w;
InitStack(S); // 初始化栈
Push(S,v);
visited[v] = true;
while(!IsEmpty(S)){
k = Pop(S); //每次出栈都是栈顶
visit(k);
for(int w = FirstNeighbor(G,k); w >= 0; w = NextNeighbor(G,k,w)){
if(!visited[w]) //层次遍历的同时,未经过栈的进栈
Push(S,w);
visited[w] = true;
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 生成最小树
# 生成树的概念
一个连通图的生成树是一个极小连通子图,它含有图中全部顶点,但只有构成一棵树的(n-1)条边。如果在一棵生成树上添加一条边,必定构成一个环。一棵有n个顶点的生成树(连通无回路图)有且仅有(n-1)条边,如果一个图有n个顶点和小于(n-1)条边,则是非连通图。如果它多于(n-1)条边,则一定有回路。但是,有(n-1)条边的图不一定都是生成树。
# 最小生成树
图的所有生成树中具有边上的权值之和最小的树。按照生成树的定义,n个顶点的连通图的生成树有n个顶点、n-1条边。
# 构造最小生成树的准则
(1)必须只使用该图中的边来构造最小生成树; (2)必须使用且仅使用n-1条边来连接图中的n个顶点; (3)不能使用产生回路的边。
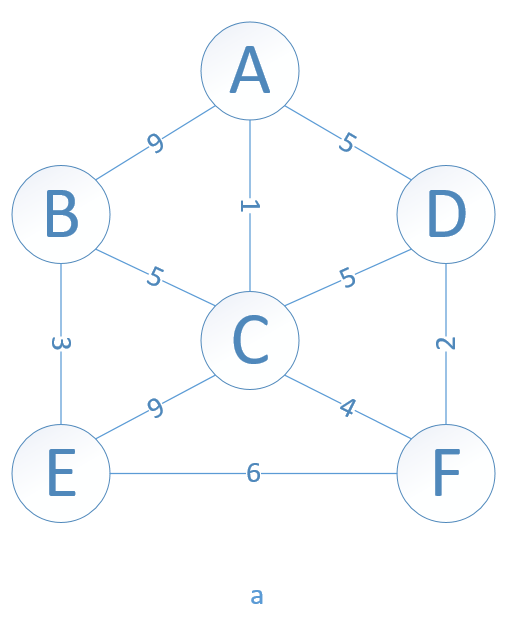
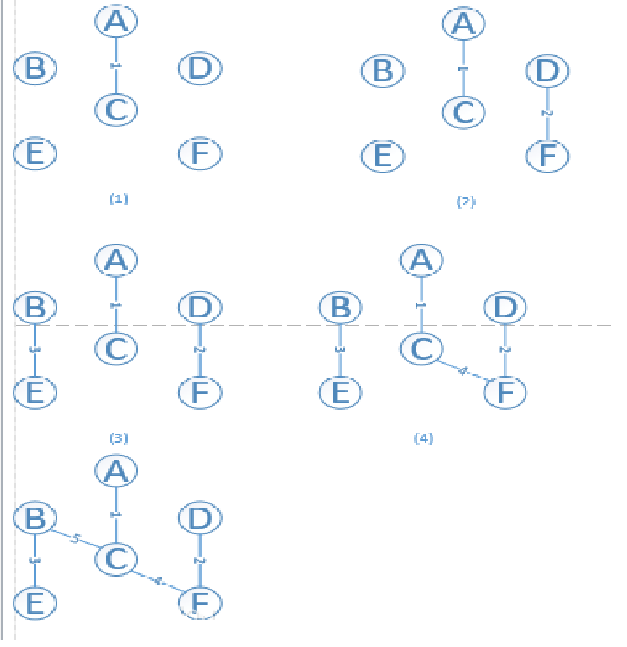
# 普里姆(Prim)算法
以一个顶点U={u0}为初态,不断寻找与U中顶点相邻且代价最小的边的另一个顶点,扩充U集合直到U=V时为止。生成过程可以如图所示,a是原图,之后是生成过程。
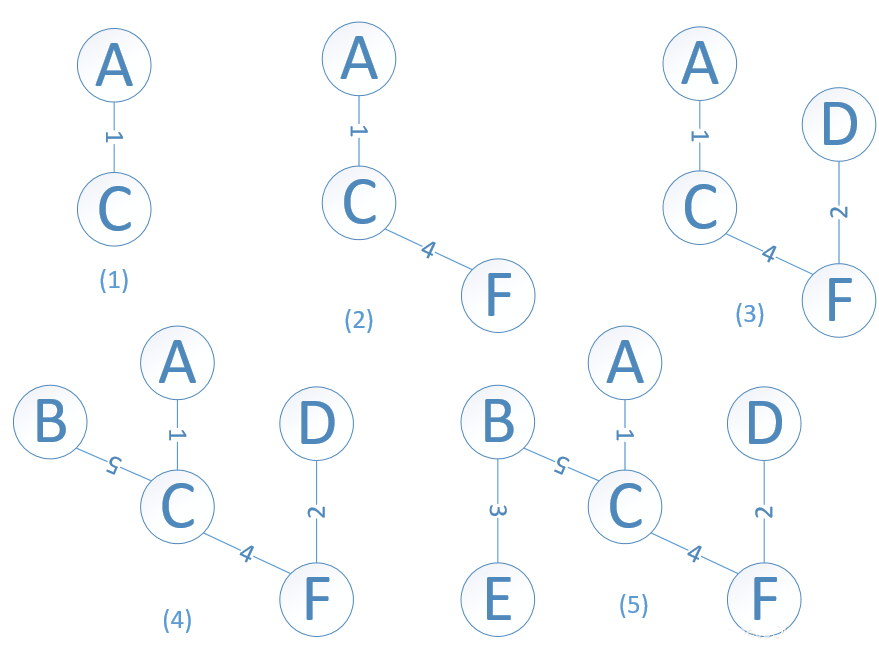
# 克鲁斯卡尔(Kruskal)算法
克鲁斯卡尔求最小生成树的思想是假设初始状态为只有n个顶点而无边的非连通图T={V,{}},图中每个顶点自成一个分量。在E中选择代价最小的边,若该边依附的顶点落在T中不同的连通分量上,则将此边加入到T中,否则舍去此边而选择下一条代价最小的边,直到T中所有顶点都在同一连通分量上为止。
# 图的最短路径问题
# 最短路径的问题阐述
最短路径问题:如果从有向图中某一顶点(称为源点)到达另一顶点(称为终点)的路径可能不止一条,如何找到一条路径使得沿此路径上各边上的权值总和达到最小。
# 单源最短路径问题
给定一个带权有向图 D 与源点 v ,求从v 到 D 中其它顶点的最短路径。限定各边上的权值大于0。
# 迪杰斯特拉(Dijkstra)算法
提出了一个按路径长度递增的次序产生最短路径的算法。首先求出长度最短的一条最短路径,再参照它求出长度次短的一条最短路径,依次类推,直到从顶点 v 到其它各顶点的最短路径全部求出为止。
# 弗洛伊德算法
弗洛伊德算法仍从图的带权邻接矩阵Edge[i][j]出发,其基本思想是:假设求顶点vi到vj的最短路径。如果从vi到vj有弧(无向图称为边),则从vi到vj存在一条长度为Edge[i][j]的路径,该路径不一定是最短路径,尚需n次试探。首先考虑路径(vi ,v0 ,vj)是否存在(即判别弧(vi ,v0 )和弧(v0 ,vj)是否存在)。如果存在,则比较(vi ,vj)和(vi ,v0 ,vj)的路径长度取长度较短者为从vi到vj的中间定点序号不大于0的最短路径。假如在路径上再增加一个顶点v1,也就是说,如果(vi ,…,v1)和(v1,…,vj)分别是当前找到的中间顶点的序号不大于0的最短路径,那么(vi ,…,v1,…,vj)就有可能是从vi到vj的中间顶点的序号不大于1的最短路径。将它和已经得到的从vi到vj中间顶点序号不大于0的最短路径相比较,从中选出中间顶点的序号不大于1的最短路径之后,再增加一个顶点v2,继续进行试探。依次类推,若vi ,…,vk)和(vk,…,vj)分别是从vi到vk和从vk到vj中间顶点的序号不大于k-1的最短路径,则将(vi ,…,vk,…,vj)和已经找到的从vi到vj且中间顶点序号不大于k-1的最短路径相比较,其长度较短者是从vi到vj的中间顶点序号不大于k的最短路径。这样,经过n次比较后,最后求得的必是从vi到vj的最短路径。按此方法,可以同时求得各对顶点间的最短路径。
# AOE网与关键路径
# AOE的概念
AOE网是一个带权的有向无环图。其中用顶点表示事件,弧表示活动,权值表示两个活动持续的时间。AOE网是以边表示活动的网。 AOV网描述了活动之间的优先关系,可以认为是一个定性的研究,但是有时还需要定量地研究工程的进度,如整个工程的最短完成时间、各个子工程影响整个工程的程度、每个子工程的最短完成时间和最长完成时间。在AOE网中,通过研究事件和活动之间的关系,可以确定整个工程的最短完成时间,明确活动之间的相互影响,确保整个工程的顺利进行。 在用AOE网表示一个工程计划时,用顶点表示各个事件,弧表示子工程的活动,权值表示子工程的活动需要的时间。在顶点表示事件发生之后,从该顶点出发的有向弧所表示的活动才能开始。在进入某个顶点的有向弧所表示的活动完成之后,该顶点表示的事件才能发生。 对一个工程来说,只有一个开始状态和一个结束状态。因此在AOE网中,只有一个入度为零的点表示工程的开始,称为源点;只有一个出度为零的点表示工程的结束,称为汇点。
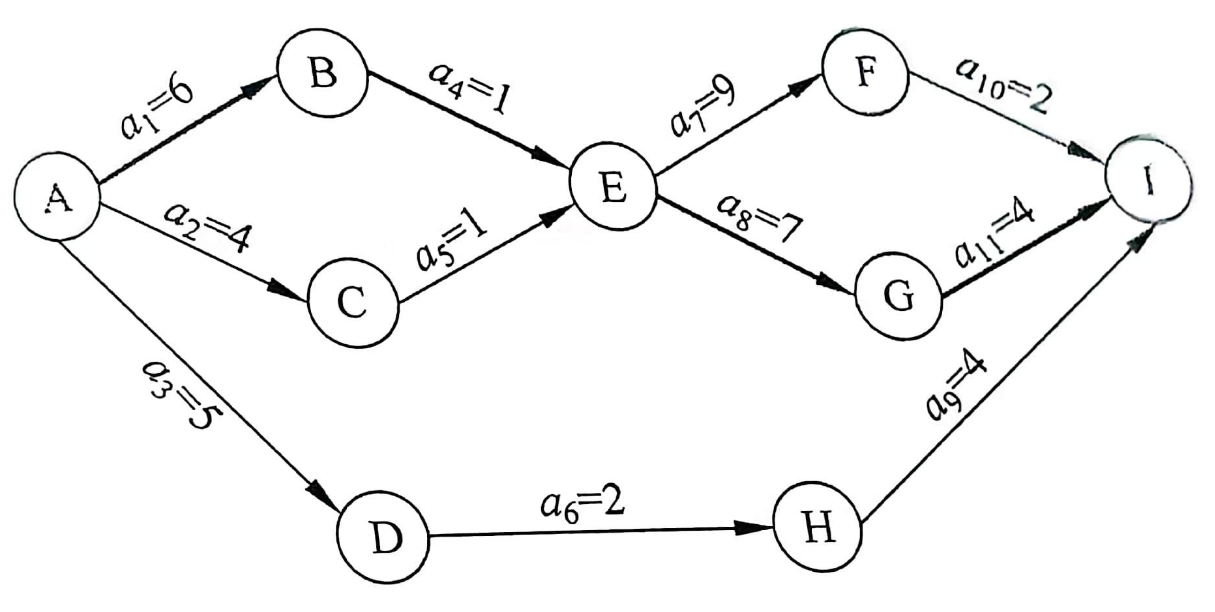
# 关键路径的概念
关键路径是指在AOE网中从源点到汇点路径最长的路径。这里的路径长度是指路径上各个活动持续时间之和。在AOE网中,有些活动是可以并行执行的,关键路径其实就是完成工程的最短时间所经过的路径。关键路径上的活动称为关键活动。
求AOE网的关键路径的步骤: 1、对AOE网中的顶点进行拓扑排序,如果得到的拓扑序列顶点个数小于网中顶点数,则说明网中有环存在,不能求关键路径,终止算法。否则,从源点v0开始,求出各个顶点的最早发生时间ve(i)。 2、从汇点vn出发vl(n-1)=ve(n-1),按照逆拓扑序列求其他顶点的最晚发生时间vl(i)。 3、由各顶点的最早发生时间ve(i)和最晚发生时间vl(i),求出每个活动ai的最早开始时间e(i)和最晚开始时间l(i)。 4、找出所有满足条件e(i)=l(i)的活动ai,ai即是关键活动。